Introduction
In this project a Deep Reinforcement Learning Algorithm is developed to increase the profits from a given stock. A supervised learning algorithm has also been implemented using classification to predict the future stock prices and maximize profits using the predictions. The results from both methods are compared.
Motivation
Machine Learning has unprecedented applications in the finance sector. The accuracy of prediction has been greatly improved with the advent of Reinforcement Learning and Artificial Intelligence. The methods explored here provide a quantitative juxtaposition of RL and Supervised Learning showing that using the former is more profitable.

Methods Explored
SVM
Support-Vector Machines are supervised learning models that analyse data for classification and regression analyses. Each data point is viewed as a p-dimensional vector and the model aims to classify these data points using a (p-1)-dimensional hyperplane. The best hyperplane is that which has the largest margin between the two classes. In case the data points are not linearly separable, we map them to a higher dimensional space where they can be easily separated. Kernel functions are used for the same, depending on the type of data in concern.
-
Linear Kernel is the best option when the dataset is linearly separable.
-
Radial Basis Function Kernel is used to map data points to an infinite-dimensional hyperspace to separate them. However, this often leads to overfitting and so we use generalisation to stop that.
-
Polynomial Kernel is used to map data points to a higher dimension by using a polynomial function of degree d. Using a higher degree tends to overfit the data.
Deep Q-Learning
Q-Learning
Reinforcement Learning is a process in which an agent is confined to an environment and tasked with learning how to behave optimally under different circumstances by interacting with the environment. The different circumstances the agent is subjected to, are called states. The goal of the agent is to know what action, amongst a set of allowed actions, must it take such as to yield maximum reward.
Q-Learning is a type of RL which uses Q-Values i.e., action values, to improve the behaviour of the agent in an iterative process. These Q-Values are defined for states and actions. Thus, Q(S, A) is an estimate of the quality of the action A at state Q. Q(S, A) can be represented in terms of the Q-value of the next state S' as follows -


This is the Bellman Equation. It shows that the maximum future reward equals the reward received by the agent for entering the current state S added to the maximum future reward for the next state S'. With Q-Learning, the Q-values can be approximated iteratively with the help of the Bellman equation. This is also called Temporal Difference or TD-Update rule -
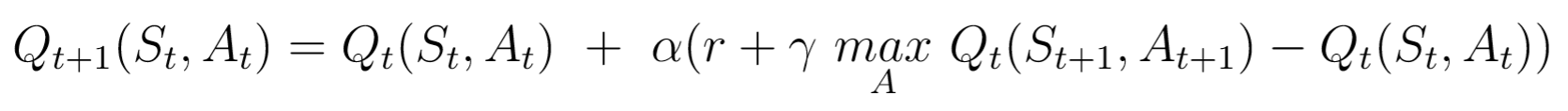 Here,
Here,
- St is the current state and At is the action picked according to the policy.
- St+1 is the next state and At+1 is the next action considered to effectively have maximum Q-value in the next state.
ris the current reward obtained on the current action.Gammahas values in the interval (0, 1] and is called the discount factor for future rewards. Future rewards are considered to be less valuable than current ones and are therefore discounted.Alphais the learning rate or the step length for updating the Q-values.
A simple policy commonly used is the E-greedy policy. Here, E is also called the exploration. This signifies -
- The agent chooses the action with the highest Q-value with a probability
1-E. - The agent chooses the action at random with a probability
E. Thus, a high exploration implies that the agent will explore more actions at random.
The “Deep” in Deep Q-Learning

Q-Learning aims to create a Q-state vs action matrix for the agent which it uses to maximize its reward. However, this is highly impractical for real-world problems where there can be a huge number of states and actions associated. To solve this problem, it is inferred that the values in the Q-matrix are related to each other. Therefore, instead of actual values, approximate values can be used so long as the relative importance is preserved. Therefore, to approximate these values, a neural network is used. Due to the incorporation of neural network, it is called Deep Q-Learning.
The working step for Deep Q-Learning is to feed the neural network with an initial state, which returns the Q-value of all possible actions as a result. Experience Replay is essentially a way of logically separating the learning phase from gaining experience. The system stores the agent’s experience et = (st, at, rt, st+1) and learns from it. This gives an advantage because the model makes use of previous experience by learning from it multiple times. When gaining real-world experience is expensive, experience replay is used to get maximum learning from previous experiences.
Therefore, Deep Q-Learning is a process in which an agent iteratively learns to maximize its reward in a given environment by exploring many possible actions at each achieved state using an E-greedy policy and a neural network to approximate Q-values.
Data
Any kind of Financial data or stock data is a timeseries value within a certain frequency interval. In this project two different frequency data have been used.
- Google data with one day frequency, downloaded from Yahoo Finance in csv form and preprocessed to convert into appropriate, usable format.
- JustDial stock data with one minute frequency has been scraped from Kite (An online trading platform) in json format. This is converted to csv and preprocessed appropriately.
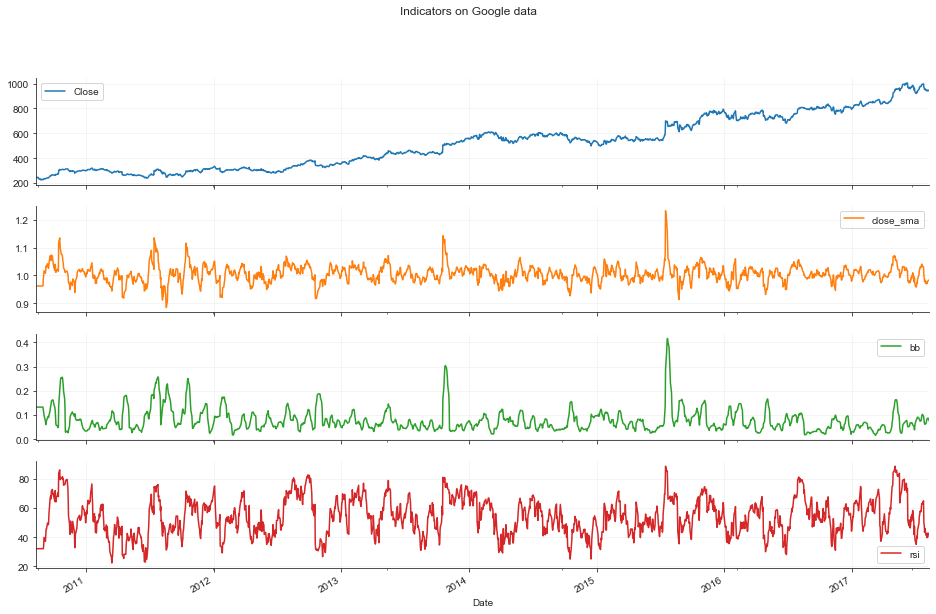
Both the stock’s data consists of Open, High, Low, Close and Volume Traded values for a particular time period. The price data in this form is not very helpful for the intended purpose. Indicators are functions which take one or more of these price values and help gain more insight into the behavior of the stock. The following three indicators are added during preprocessing to augment the data -
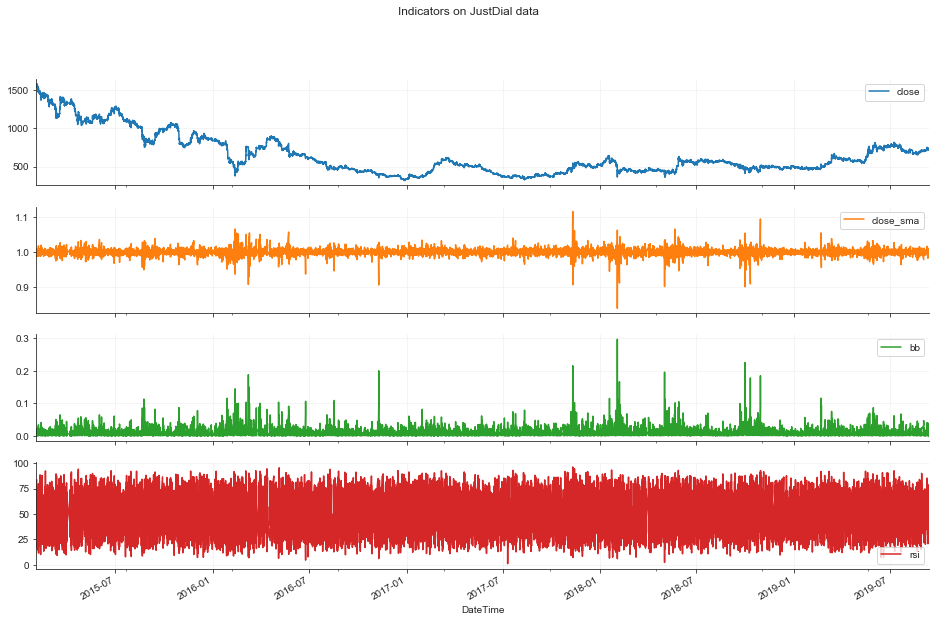
- Close/SMA
- Close value and Simple Moving Average alone cannot give much information to act upon, but when combined, the ratio Close/SMA gives us the trend of the price moment reacting to even small changes.
- Bollinger Band Value
- Bollinger Bands are two lines drawn at two standard deviations apart: Upper band, Middle band, and Lower band. The Middle band is a moving average line. The BB value is calculated using these three values as (UpperBand-LowerBand)/MiddleBand
- RSI
- Relative Strength Index is a momentum index that indicates the magnitude of recent changes in the price that evaluate to over-bought and over-sold conditions.
These indicators are calculated using TA-lib library.
Google stock data
Price Plot
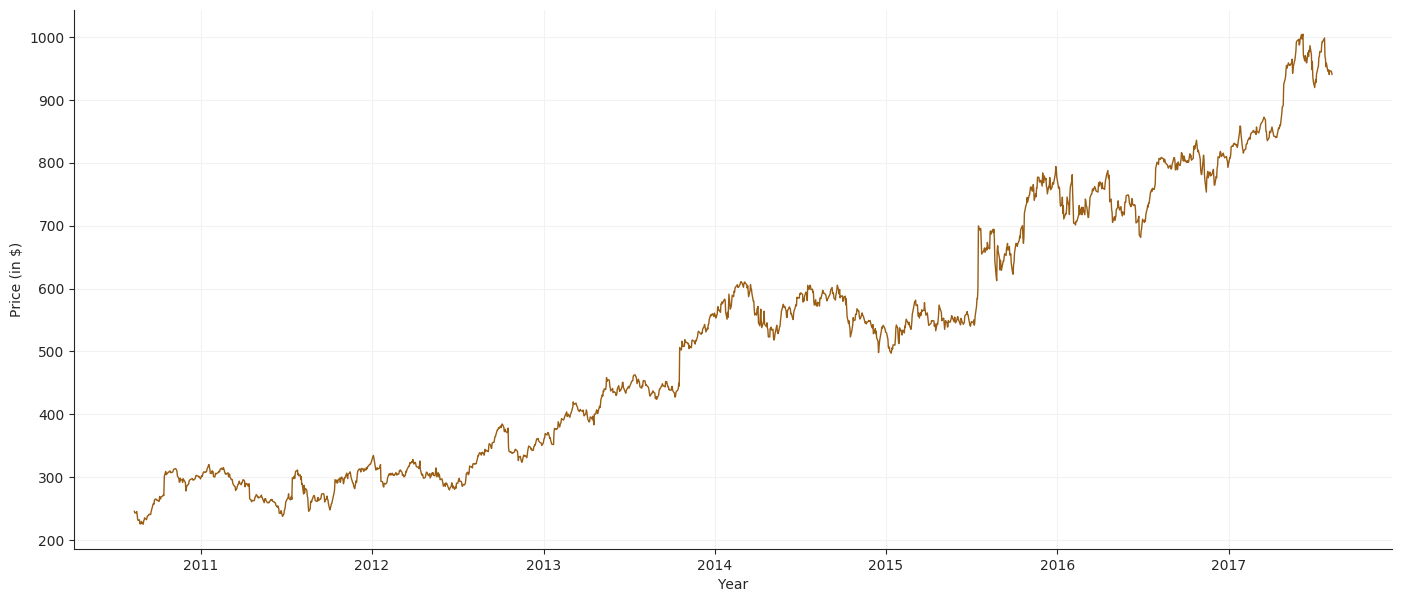
Volume Plot
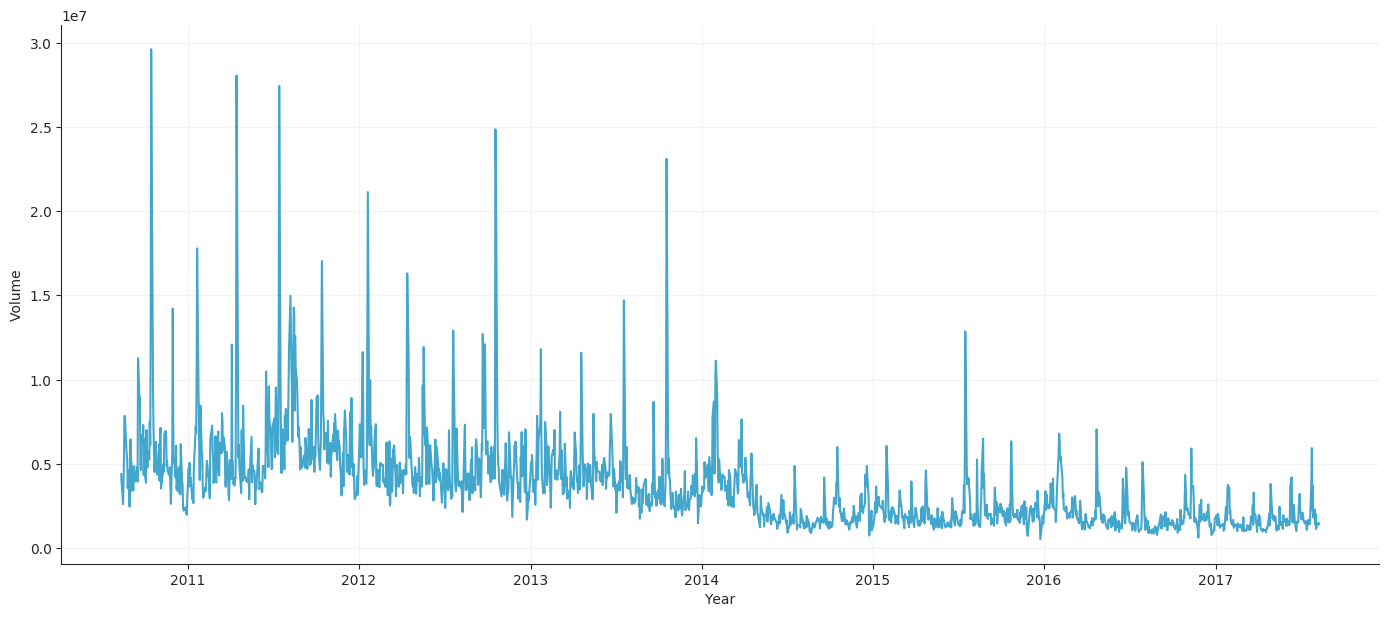
Indicators Plot
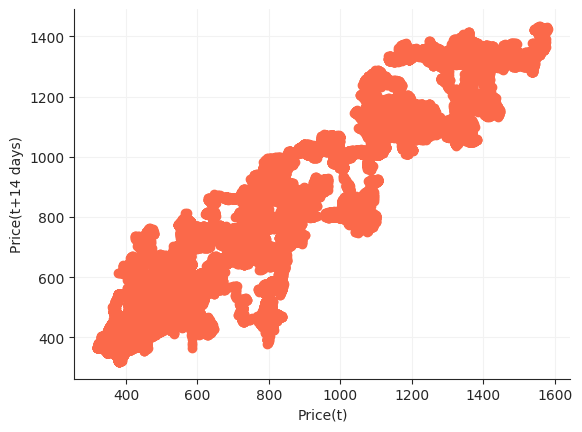
Lag Plot
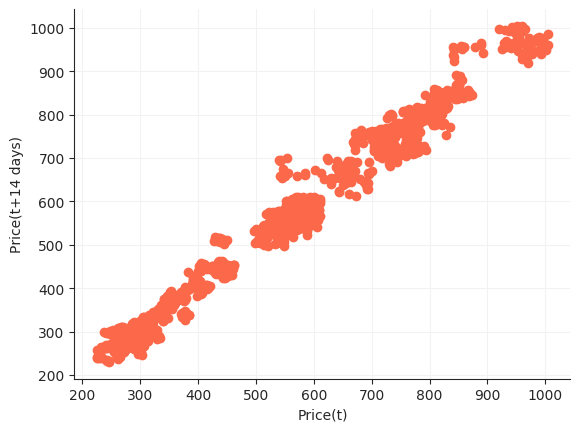
Just Dial stock data
Price Plot
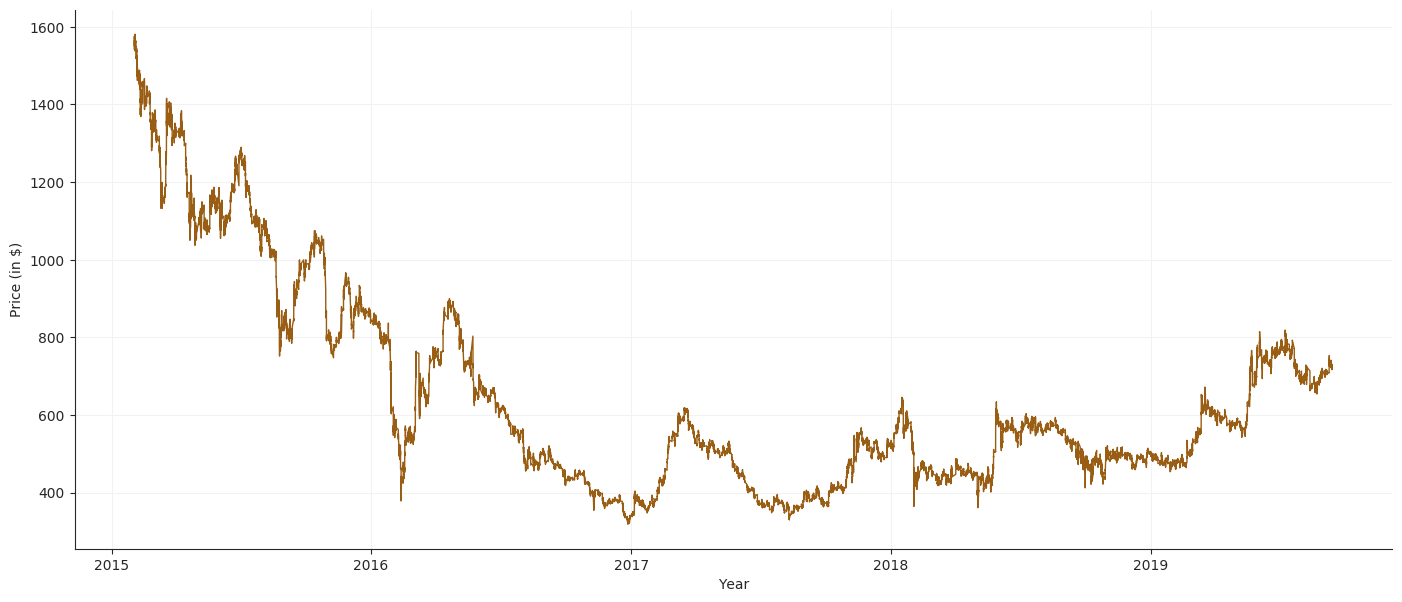
Volume Plot
Indicators Plot
Lag Plot
Libraries
Tensorforce
Tensorforce is an open source Deep Reinforcement Library that abstracts Reinforcement Learning Primitives with Tensorflow backend. It provides modularity and gives us the freedom to concentrate on the application rather than the specific implementation of the algorithm which is similar for every application. There are four high-level abstractions: Environment, Agent, Runner and Model. The Model abstraction sits inside the Agent and gives us the ability to change the internal mechanisms of the Agent itself. The Environment abstract is to help create custom user environment details. Runner is used to execute the model.
import tensorforce.agents import agents
import tensorforce.environments import Environment
#create and initialize environment
environment = Environment.create(environment=Environment)
#Create agent
agent = Agent.create(agent=agent)
agent.initialize()
states = environment.reset()
agent.reset()
while not terminal:
actions = agent(states=states)
next_state, terminal, reward = environment.execute(actions)
agent.observe(reward=reward, terminal=terminal)
agent.close()
environment.close()
The Environment class is created by inheriting the Environment abstract. The agent is created by providing required parameters as an input for the Agent class. The agent initialization creates a tensorflow network and initializes all the network connections along with the memory required to store the state variables and action rewards.
The agent returns actions based on the state variables passed to it. These actions are passed to the environment. The environment executes these actions and returns the reward associated with that action and also prompts if it is the terminal state. The agent then observes the reward and stores it in its memory for further use.
Methodology
SVM
For both the datasets an additional set of indicators are defined, on top of those defined for Reinforcement Learning -
- O-C
- Defines the difference between opening and closing prices.
- STD_10
- This is the Standard Deviation with a rolling window 10.
The decision labels are decided according to the trend in the market close prices.
- If the next close price is higher than the current close price, the model decides to buy. This is because the price is expected to further rise, thus increasing the value of stocks possessed.
- If the next close price is lesser than the current close price, the model decides to sell. This is done to minimize losses incurred in the expected eventuality where the price continues to fall.
The predictions are then simulated with testing data starting with some base cash and no stocks and the cumulative profits at the end of each cycle are monitored. The simulation works on two basic conditions:
- If the model predicts sale of stocks and number of stocks owned is not 0, the agent sells at the current price. The profit is calculated as the difference between the current price and the price at which stocks were bought. The profit is also added to the cash possessed.
- If the model predicts purchasing of stocks and the agent has enough monetary reserves, the purchase is made at the current price (this is henceforth stored as the cost price of the stock) and the cash reserves are depleted accordingly.
The cumulative profit is calculated at the end and plotted.
DQN
Before conducting the experiments, the Agent and the Environment are created.
Creating the Trading environment:
The environment is created by inheriting from the Environment abstract has 6 states and 3 actions.
These actions are Buy, Sell and Hold. The actions are only performed when a specific condition is met (Example - The agent cannot Sell without having any stocks in its inventory).
The 6 states are -
- Cumulative Profits till the current timestep,
- Stocks Held, boolean value,
- Price Vector, including current price and 10 previous prices,
- Close/SMA,
- BB value
- RSI.
Execution method:
When the agent gives actions to the environment it will execute the actions and change the environment’s states thus:
- Buy, if no stocks exists and there is enough cash.
- Sell, if stocks exist or it is the final timestep.
- Hold stocks, if stock exists.
Reward Function:
- Buy reward granted is equal to one-tenth of the current stock price.
- Sell reward is equal to two times the profit gained by selling the stock.
- Hold Reward is awarded depending on the current price. If the current price is more than previous then the reward is one-twentieth of current price and if the current price is less, a negative reward of one-fiftieth of the current price is given.
Creating the DQN Agent:
A DQN Agent is created with a Deep Neural Network of LSTM, CNN and Dense network Layers.
Deep Network specifications:
- 128 x 4 LSTM Network with relu activation.
- 128 x 1 CNN Network with relu activation.
- 128 x 1 Dense Network with relu activation.
Agent Specifications:
- Learning Rate = 0.0001
- Discount Factor = 0.9
- Epsilon Decay factor = 0.4 (units: Episodes)
- Replay Memory Size = maximum timesteps in an episode
Experiment:
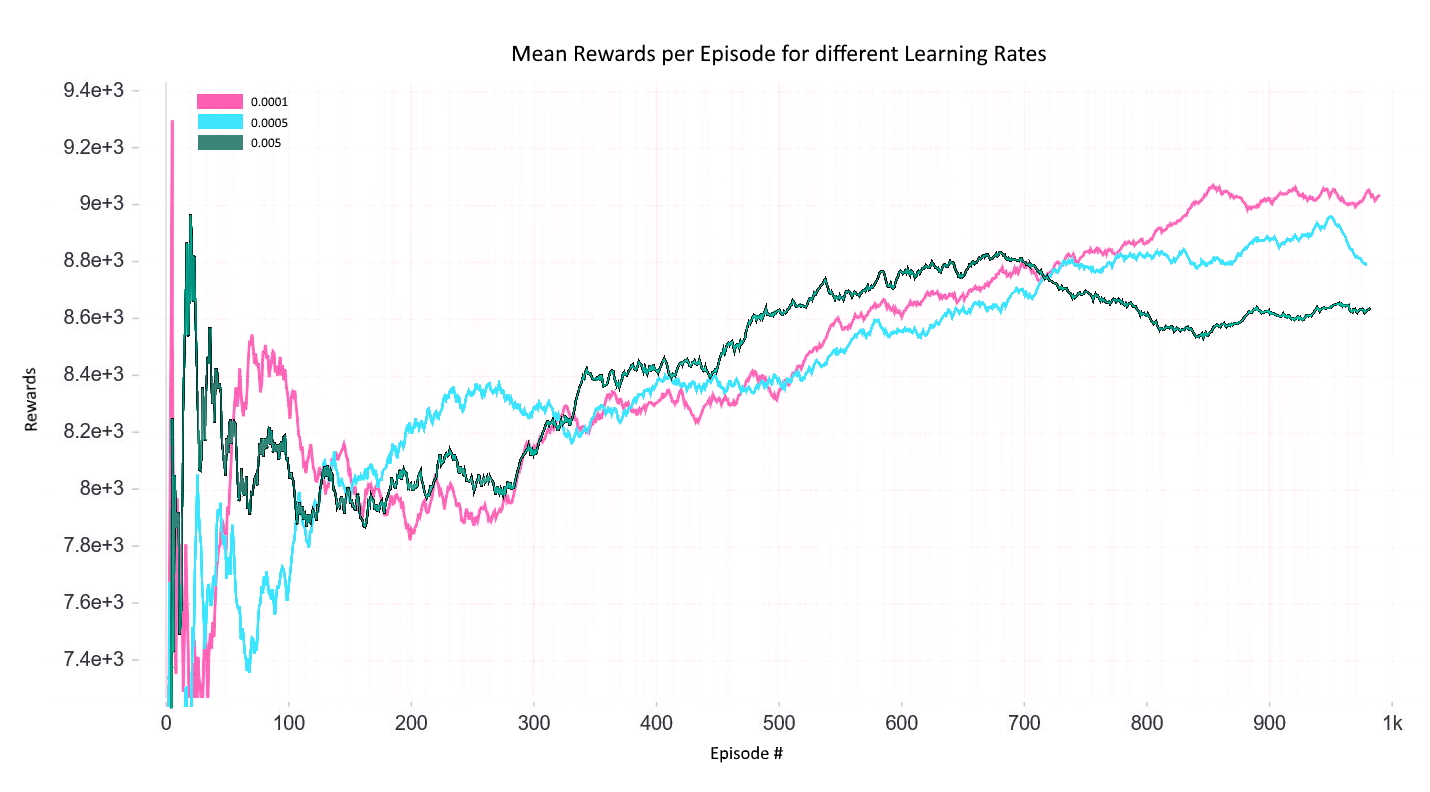
The agent and the environment are initialized with the above specifications. The epsilon decay rate makes sure that the agent explores different states and stores them in memory for retrieving them later by executing an experience replay. The Learning Rate has a huge effect on the performance of the agent, hence, different learning rates have been tried and the best learning rate has been selected. The agent has been trained on 1000 episodes with the above specifications. The mean rewards per episode are as follows:
Reward Graph with different Learning Rates
Results
DQN
Test data Plot for 100 episodes after training the agent on Google Train data.
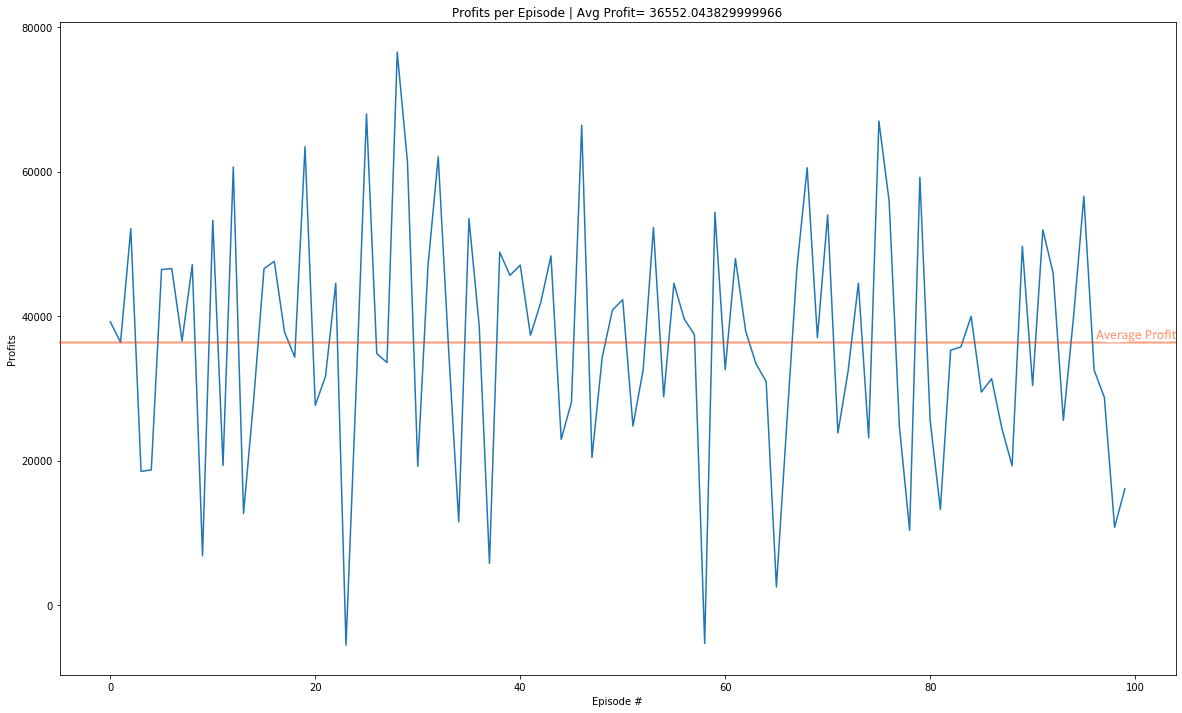 Over the 100 episodes the agent’s profits were less than zero only twice.
Over the 100 episodes the agent’s profits were less than zero only twice.
Google Test Data
Single episode Buy Sell Graph for Google:
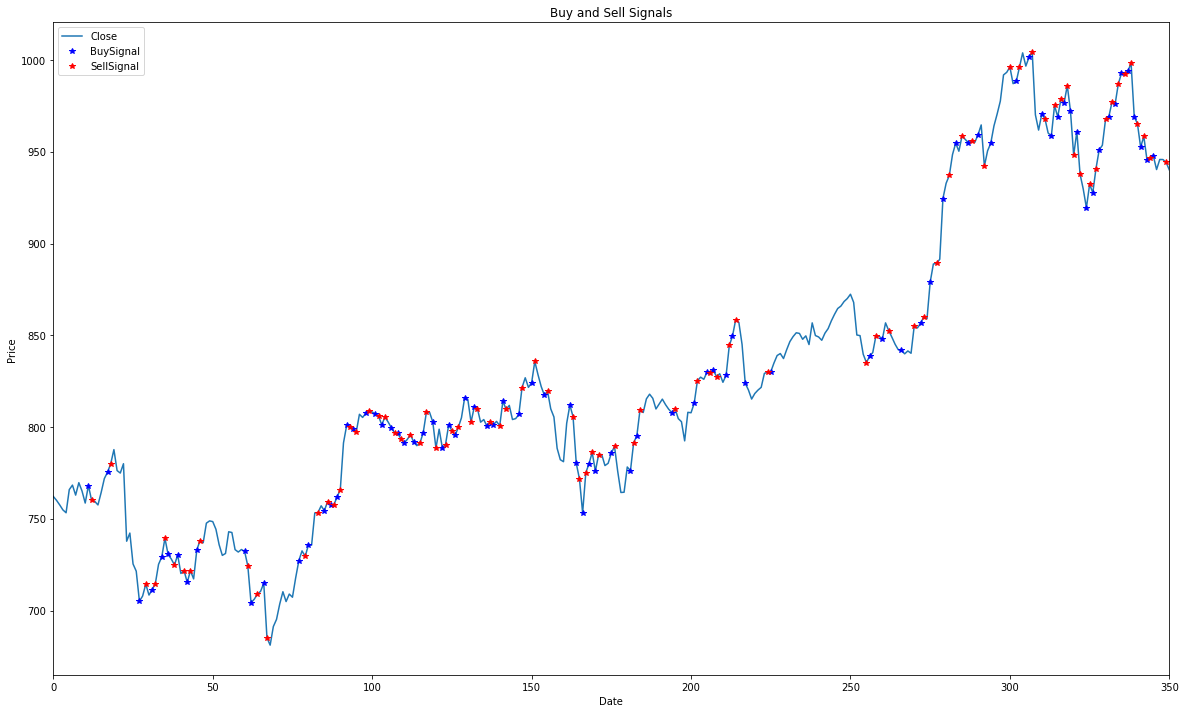
Single episode Reward Value Graph for Google:
JustDial Test Data
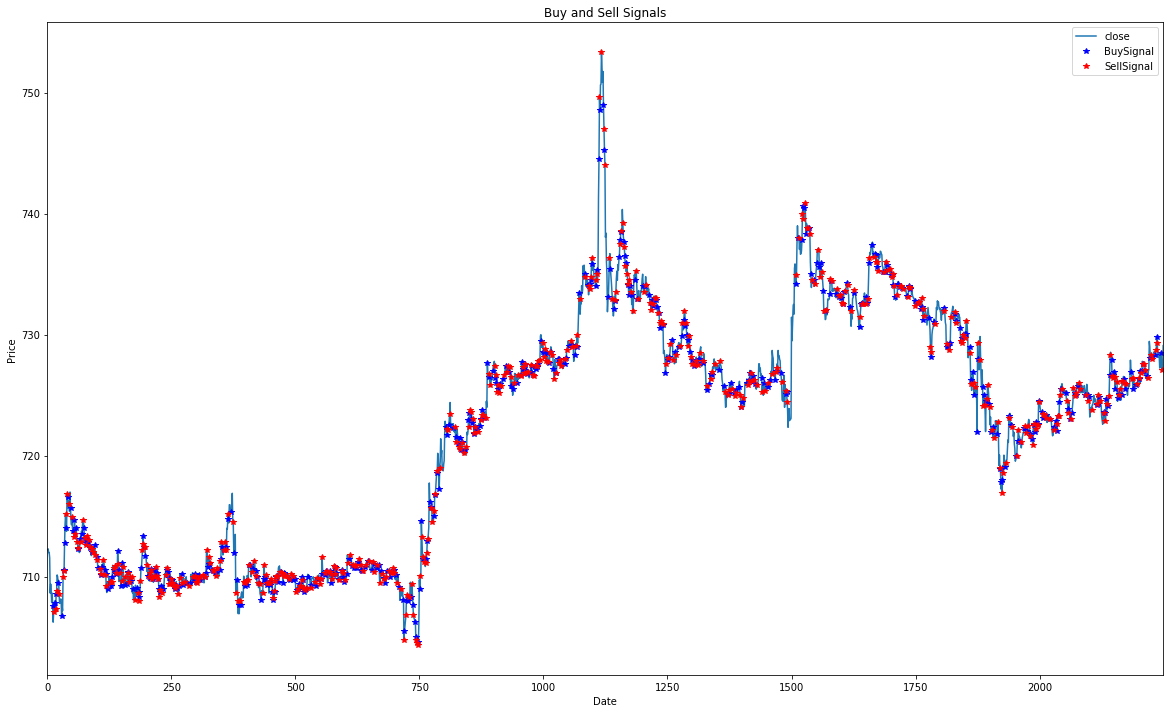
Single episode Buy Sell Graph for JustDial:
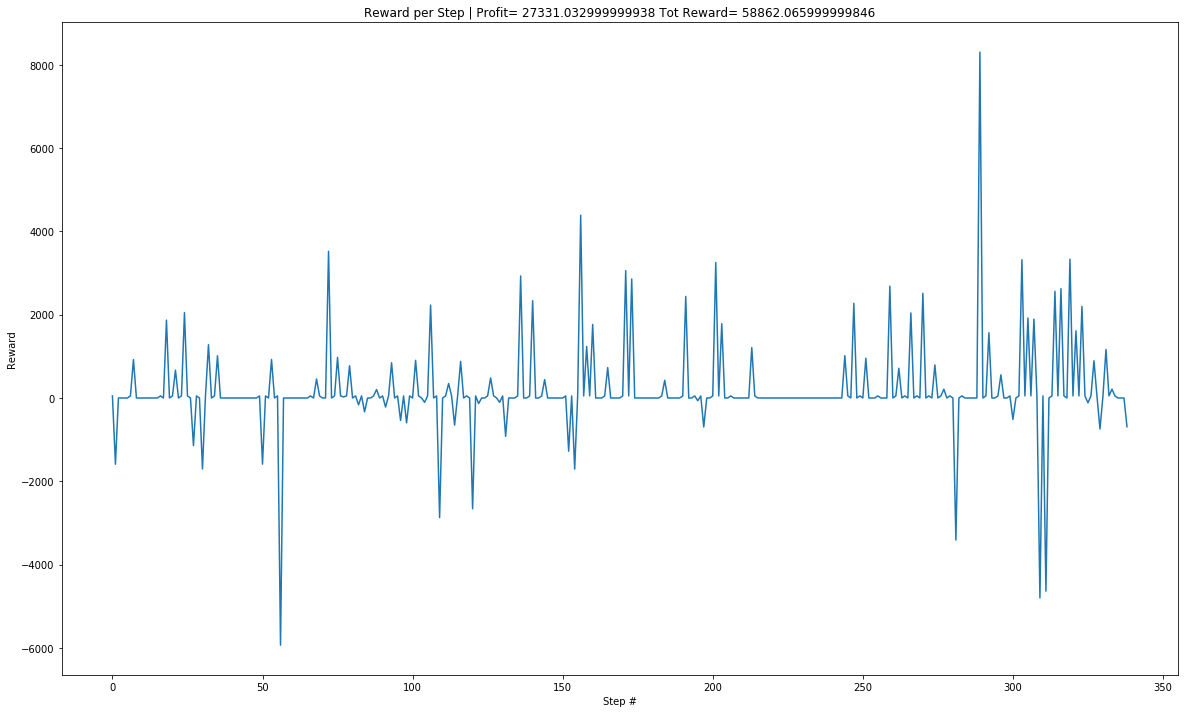
Single episode Reward Value Graph for JustDial:
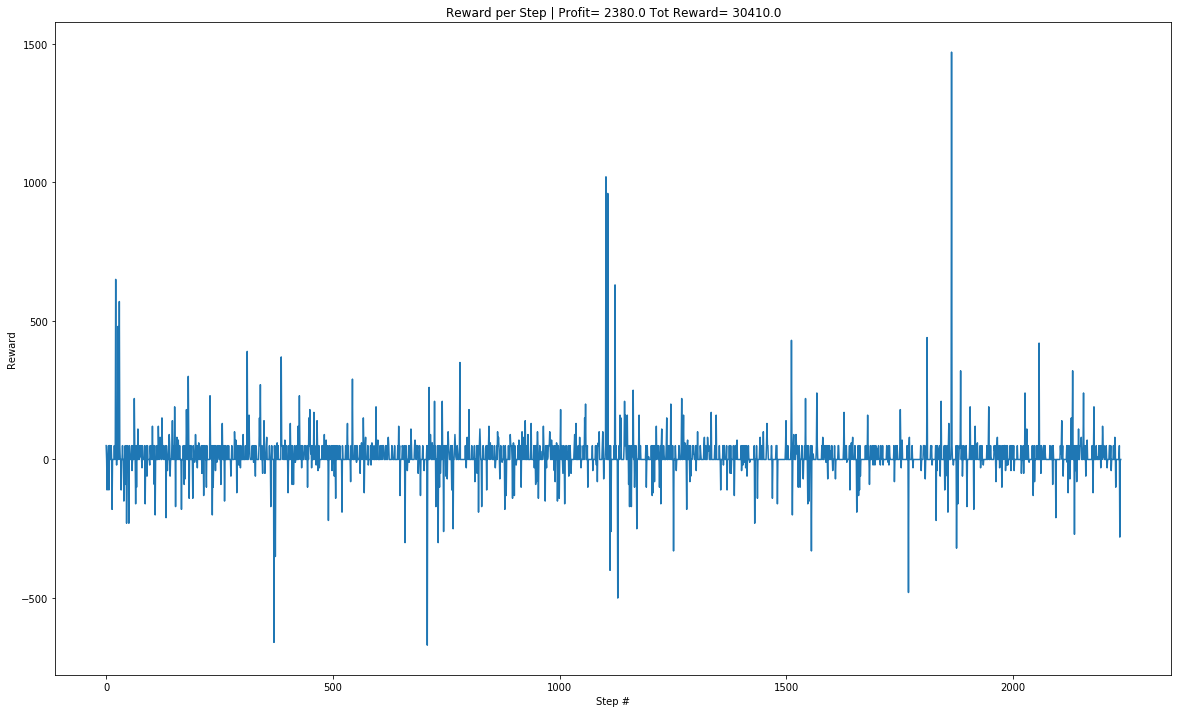
DQN agent shows promise of getting better with more computing power and learning time.
SVM
Buy Sell Graph for Google Data
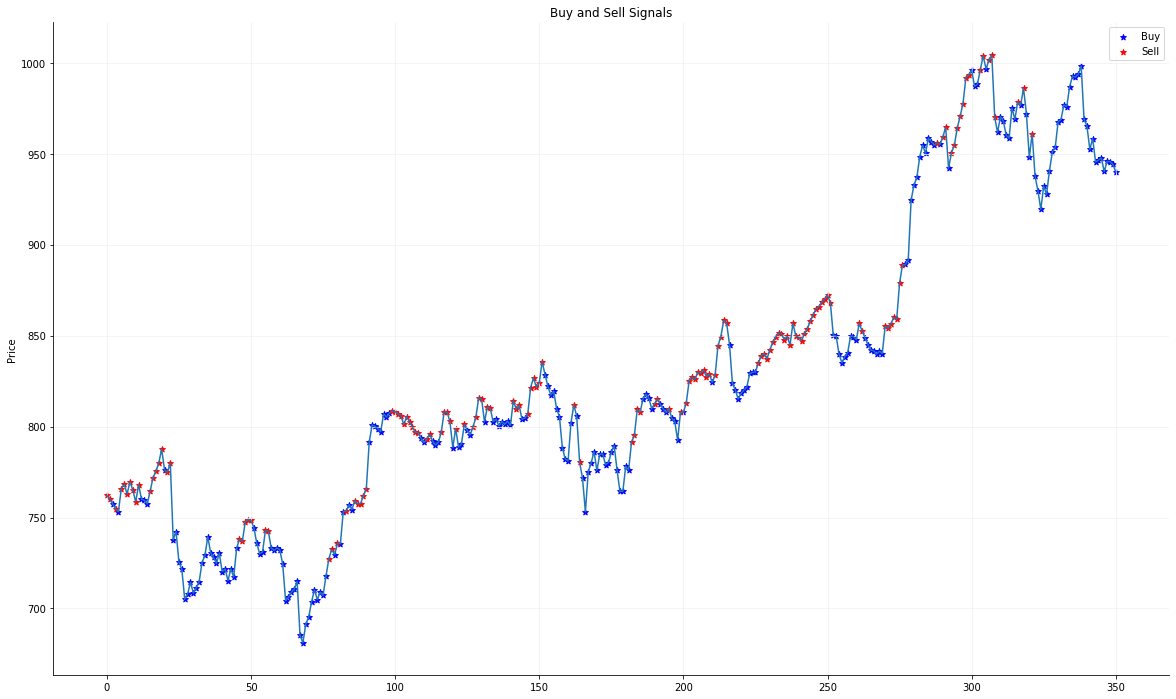
Buy Sell Graph for JustDial Data
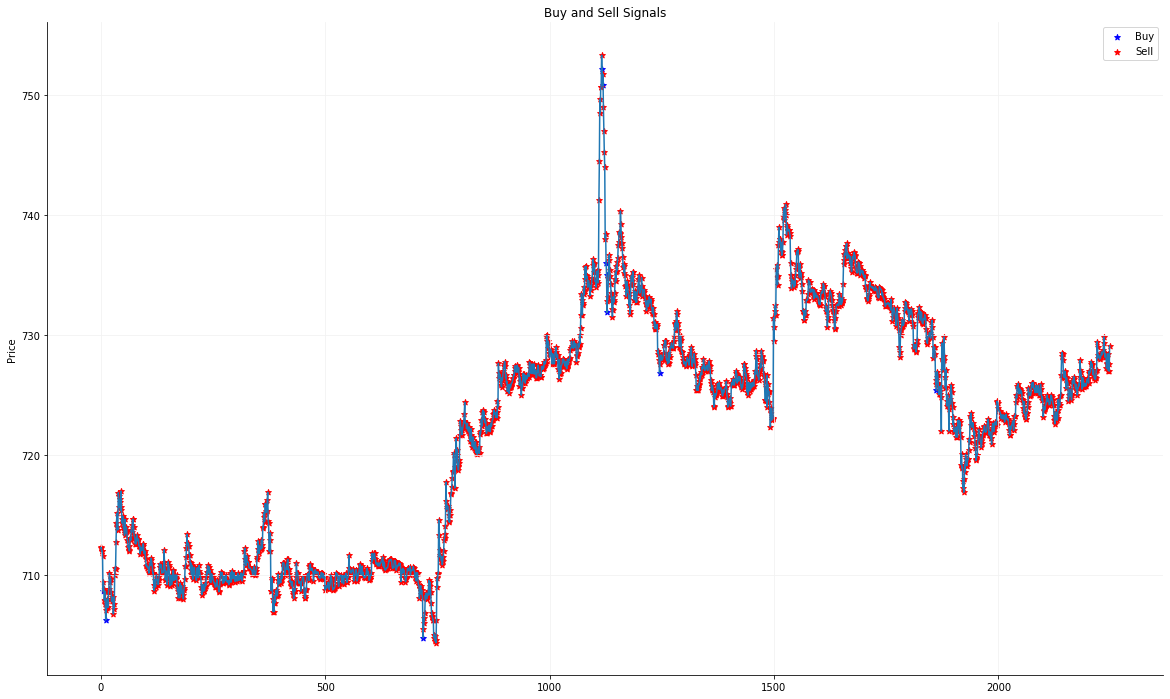
Google Test Data
Linear Kernel Plot
Profit Trend:

Cumulative Profit Trend:

Radial Basis Function Kernel Plot
Profit Trend:

Cumulative Profit Trend:

Polynomial Kernel Plot
Profit Trend:

Cumulative Profit Trend:

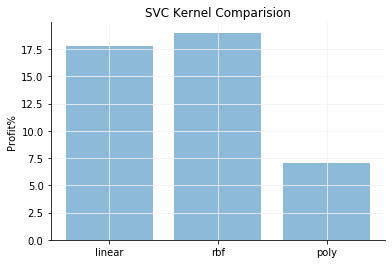
Comparison of different Kernels
JustDial Test Data
Linear Kernel Plot
Profit Trend:

Cumulative Profit Trend:

Radial Basis Function Kernel Plot
Profit Trend:

Cumulative Profit Trend:

Polynomial Kernel Plot
Profit Trend:

Cumulative Profit Trend:

Comparison of different Kernels
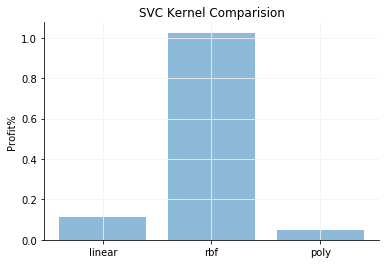
Analysing the graphs shows that the RBF Kernel provides maximum profits.
Comparison between DQN and SVC - Protfolio Returns
| - | DQN | SVC |
|---|---|---|
| 27.3 % | 19 % | |
| JustDial | 2.38 % | 1.1 % |
Conclusion
We infer that Reinforcement Learning performs better than Support Vector Machine.

References
- Xiong, Z., Liu, X., Zhong, S., Yang, H., & Elwalid, A. (2018). Practical Deep Reinforcement Learning Approach for Stock Trading. ArXiv, abs/1811.07522.
- Li, Y. (2017). Deep Reinforcement Learning: An Overview. ArXiv, abs/1701.07274.
- Azhikodan, Akhil & Bhat, Anvitha & Jadhav, Mamatha. (2019). Stock Trading Bot Using Deep Reinforcement Learning. 10.1007/978-981-10-8201-6_5.
- Jiang, Z., Xu, J.D., et al. A Deep Reinforcement Learning Framework for the Financial Portfolio Management Problem. ArXiv:1706.10059, 2017.
- Playing Atari with Deep Reinforcement Learning, Volodymyr Mnih and Koray Kavukcuoglu and David Silver and Alex Graves and Ioannis Antonoglou and Daan Wierstra and Martin Riedmiller,arXiv, 2013
- Mnih, V., et al., Playing atari with deep reinforcement learning. arXiv preprint arXiv:1312.5602, 2013.
- Silver, D., et al., Mastering the game of go without human knowledge. Nature, 2017.550(7676): p. 354.
- Hochreiter, S. and J. Schmidhuber, Long short-term memory. Neural computation, 1997.9(8): p. 1735-1780.
- Gers, F.A., J. Schmidhuber, and F. Cummins, Learning to forget: Continual prediction with LSTM. 1999.
- Gers, F.A., D. Eck, and J. Schmidhuber, Applying LSTM to time series predictable through time-window approaches, in Neural Nets WIRN Vietri-01. 2002, Springer. p. 193-200.
- Malhotra, P., et al. Long short term memory networks for anomaly detection in time series.in Proceedings. 2015. Presses universitaires de Louvain.
- Lipton, Z.C., et al., Learning to diagnose with LSTM recurrent neural networks. arXiv preprint arXiv:1511.03677, 2015.
- Cho, K., et al., Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078, 2014.
- Chung, J., et al., Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.